上海羊羽卓进出口贸易有限公司
上海羊羽卓进出口贸易有限公司📅 2026年04月09日 14:23 发布于北京
【标题】2026选科AI助手技术全解:原理、代码示例与面试考点

一、开篇引入
新高考改革持续推进,选科组合从“3+3”到“3+1+2”,不同高校专业的选科要求日趋复杂,学生面临的决策压力前所未有。2026年春季学期起,AI大模型在教育场景的应用已从试点走向制度化部署,选科AI助手作为其中重要一环,正成为连接学生个性化需求与高校专业选择的关键桥梁-48。
但不少学习者和开发者在接触这个方向时,常常遇到这样的困境:知道AI选科工具“能用”,却说不清它“怎么工作”;听过RAG、知识图谱这些术语,却搞不懂它们之间是什么关系;面对面试官问“传统推荐和LLM推荐的区别”,只能给出零散的回答。本文将从技术科普出发,结合原理讲解与代码示例,系统梳理选科AI助手的核心技术体系,帮你建立从概念到落地、从原理到考点的完整知识链路。
本文将围绕以下结构展开:痛点切入→核心概念(RAG)→关联概念(知识图谱)→关系梳理→代码示例→底层原理→面试要点。
二、痛点切入:传统选科方案的局限
2.1 传统推荐系统的困境
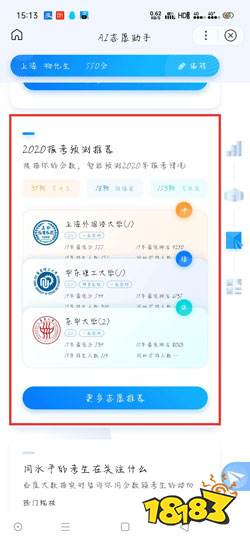
在选科AI助手出现之前,学生获取选科建议的路径主要有三种:学校提供的Excel选科指南、通用引擎的零散信息、付费的志愿填报软件。这些方式本质上仍停留在信息检索阶段,核心逻辑是“输入分数→匹配院校专业→输出结果”。
传统推荐系统在选科场景中暴露了四个典型短板:
语义理解薄弱:系统只能识别关键词标签(如“AI”“计算机”),却无法理解“我对物理感兴趣但数学偏弱”这类复合语义需求-38。
冷启动困境:新用户缺乏历史选科数据,传统协同过滤算法完全失效,只能推送热门组合-38。
数据稀疏问题:课程与课程之间的先修依赖、知识点关联等结构性信息难以被有效建模-22。
志愿排序盲区:多数产品仅根据分数圈定院校专业范围,完全忽视了决定录取结果的核心变量——志愿顺序-14。
2.2 传统选科方案的代码示例
传统选科推荐方案(基于协同过滤的简化示例) def traditional_course_recommend(user_id, all_courses, history_matrix): """ 传统推荐算法:基于协同过滤的选科推荐 局限:冷启动无法处理、无法理解语义需求、依赖密集交互数据 """ Step 1: 获取当前用户的历史选科记录 if user_id not in history_matrix: 冷启动问题:新用户无历史数据,只能返回热门课程 return sorted(all_courses, key=lambda c: c['popularity'], reverse=True)[:5] Step 2: 寻找相似用户(协同过滤核心) similar_users = find_top_k_similar_users(user_id, history_matrix, k=10) Step 3: 聚合相似用户的选科记录 recommendations = {} for sim_user in similar_users: for course in sim_user['selected_courses']: if course not in recommendations: recommendations[course] = 0 recommendations[course] += sim_user['similarity_score'] Step 4: 按分数排序返回 return sorted(recommendations.items(), key=lambda x: x[1], reverse=True)[:5] 问题:用户问“我想学人工智能方向但数学不太好怎么办”? 传统方案完全无法理解这个语义需求,只能返回“计算机类”标签下的课程
缺陷总结:传统方案本质是行为匹配而非需求理解,只能基于用户“做过什么”做推荐,无法理解用户“想要什么”。
2.3 新技术出现的必然性
正是在这个背景下,选科AI助手应运而生。与传统方案不同,选科AI助手以大语言模型(Large Language Model,LLM)为核心引擎,结合检索增强生成(Retrieval-Augmented Generation,RAG)与知识图谱(Knowledge Graph,KG)等技术,实现了从“信息匹配”到“智能决策”的能力跃迁。
三、核心概念讲解:检索增强生成(RAG)
3.1 标准定义
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种将信息检索与大语言模型生成能力相结合的技术框架。其核心思想是:在LLM生成答案之前,先从外部知识库中检索相关的上下文信息,再将这些信息作为“参考资料”输入LLM,让模型基于“检索结果+自身知识”生成更准确、更具时效性的回答-3。
3.2 关键词拆解
检索(Retrieval) :从向量数据库等外部知识库中查找与用户问题最相关的内容片段。
增强(Augmented) :将检索到的内容作为额外上下文,“增强”LLM的输入信息量。
生成(Generation) :LLM基于增强后的输入生成自然语言回复。
3.3 生活化类比
想象你要回答一个关于“新高考选科政策”的问题:
纯LLM模式:像一名只靠课堂记忆答题的学生——记忆可能过时,细节可能模糊。
RAG模式:像一名配备了“可随时查阅参考书”的学生——遇到问题先翻书查找相关资料,再结合自己的理解给出答案。
在选科AI助手中,RAG技术让模型能正确读取并理解庞杂的校务资料与选科政策,告别“无答案生成”或“信息过时”的问题-1。
3.4 RAG的价值与解决的问题
RAG解决了纯LLM模式的三个核心缺陷:知识过时(LLM训练数据截止于某个时间点)、幻觉问题(LLM可能生成看似合理但不正确的内容)、缺乏限定知识(无法访问机构内部数据库)。通过限定知识的设计,RAG确保了AI回答的正确性-3。
四、关联概念讲解:知识图谱(KG)
4.1 标准定义
知识图谱(Knowledge Graph,KG) 是一种用图结构(节点+边)来表示实体之间关系的知识表示方法。在选科场景中,知识图谱可以建模“课程—专业—先修课程—高校”之间的复杂关联网络-5。
4.2 RAG与KG的关系
RAG和知识图谱不是二选一的替代关系,而是协作关系:
| 维度 | RAG | 知识图谱 |
|---|---|---|
| 本质 | 检索+生成的架构模式 | 结构化的知识表示方法 |
| 数据形式 | 非结构化文本(文档、政策文件) | 结构化三元组(实体-关系-实体) |
| 优势 | 处理自然语言、生成连贯回答 | 精准推理、关系追踪、可解释性强 |
| 局限 | 无法进行复杂逻辑推理 | 生成能力有限 |
在选科AI助手中,两者的典型协作模式是:知识图谱提供结构化的关系推理(如“A课程是先修B课程的前提”),RAG负责从非结构化文档中检索补充信息(如“某高校2026年最新的选科要求”),最后由LLM融合二者生成个性化推荐-5。
五、概念关系与区别总结
一句话记忆:RAG解决的是“怎么找参考资料”的问题,知识图谱解决的是“知识之间怎么关联”的问题,两者共同构成选科AI助手的知识底座。
技术栈关系图(思维模型):
用户自然语言提问:“我想学人工智能,该选哪些科目?” ↓ 【意图识别与路由】 ↓ ┌───────────────┼───────────────┐ ↓ ↓ 【RAG检索路径】 【KG推理路径】 从政策文档、校务资料中 从课程关系图中查找: 检索“人工智能专业选科要求” “计算机类→物理必选” “高校录取数据”等 “AI方向→数学/编程基础” ↓ 【LLM融合生成】 综合两路信息,生成个性化选科建议
六、代码示例:选科AI助手核心流程
下面展示一个简化的选科AI助手核心模块实现:
""" 选科AI助手核心引擎 - 基于RAG + LLM的选科推荐(演示代码) 技术栈:Python 3.9+, LangChain, ChromaDB, OpenAI API """ import os from typing import List, Dict from langchain.embeddings import OpenAIEmbeddings from langchain.vectorstores import Chroma from langchain.chat_models import ChatOpenAI from langchain.chains import RetrievalQA class CourseSelectionAI: """选科AI助手核心类""" def __init__(self, policy_docs_path: str): Step 1: 初始化Embedding模型(将文本转为向量) self.embeddings = OpenAIEmbeddings(model="text-embedding-3-small") Step 2: 加载政策文档并构建向量数据库 包含:各高校专业选科要求、学科能力评估标准、升学数据 self.vector_store = self._build_vector_store(policy_docs_path) Step 3: 初始化LLM(选科推荐的核心生成引擎) self.llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.3) Step 4: 构建RAG链 - 检索 + 增强 + 生成 self.qa_chain = RetrievalQA.from_chain_type( llm=self.llm, chain_type="stuff", 将所有检索结果拼接输入 retriever=self.vector_store.as_retriever(search_kwargs={"k": 5}) ) def _build_vector_store(self, docs_path: str) -> Chroma: """将选科政策文档向量化存储""" 实际实现:读取文档 → 文本分块 → Embedding → 存入向量库 这里简化为加载已有向量库 return Chroma( persist_directory=docs_path, embedding_function=self.embeddings ) def recommend(self, user_query: str, user_profile: Dict) -> str: """ 核心推荐方法:RAG检索 + LLM生成 输入示例: user_query = "我物理成绩前10%,想报考计算机类专业,但数学中等,该怎么选科?" user_profile = {"physics_rank": "top10", "math_level": "medium", "target_major": "CS", "region": "new_gaokao_3_1_2"} """ Step 5: 增强用户查询(融入个人画像信息) enhanced_query = f""" 用户画像:物理成绩{user_profile['physics_rank']},数学水平{user_profile['math_level']}, 目标专业{user_profile['target_major']},高考模式{user_profile['region']} 用户问题:{user_query} 请结合选科政策文档,给出个性化的选科建议,包括: 1. 推荐选科组合及理由 2. 可报考的专业范围 3. 备选方案(如有) """ Step 6: RAG检索+生成 执行流程:向量检索相关文档 → LLM基于文档内容生成回答 response = self.qa_chain.run(enhanced_query) return response def knowledge_graph_reasoning(self, course_name: str) -> List[str]: """ 知识图谱推理模块(简化示例) 功能:查询某课程的先修依赖关系 """ 实际实现:使用图数据库(如Neo4j)存储课程关系 这里用字典模拟知识图谱 prerequisites_graph = { "人工智能导论": ["Python编程", "线性代数"], "机器学习": ["人工智能导论", "概率论"], "深度学习": ["机器学习", "高等数学"] } return prerequisites_graph.get(course_name, []) 运行示例 if __name__ == "__main__": 初始化选科AI助手 assistant = CourseSelectionAI(policy_docs_path="./course_policy_db") 用户场景:物理强但数学一般的同学 user_profile = { "physics_rank": "top10%", "math_level": "medium", "target_major": "CS", "region": "new_gaokao_3_1_2" } 获取推荐建议 advice = assistant.recommend( "我想学人工智能专业,但数学成绩只是中等,有什么选科建议?", user_profile ) print("=== AI选科建议 ===\n", advice)
关键步骤注释:
Step 1-3:构建向量数据库和RAG链,这是“检索”能力的基石。
Step 5:用户画像注入,实现个性化增强。
Step 6:RAG执行,融合检索结果与LLM生成能力。
七、底层原理与技术支撑
选科AI助手的高效运转,底层依赖三大技术支柱:
7.1 大语言模型(LLM)
LLM是选科AI助手的“大脑”,负责理解用户自然语言、生成个性化推荐。2026年的主流方向包括:
生成式推荐:将下一个项目预测重新表述为自回归序列生成任务,利用LLM的表达能力实现更精准的推荐-。
双通道架构:如LE-DLCM框架,通过解耦的学习者建模与课程建模,在MOOCCube等数据集上实现了NDCG@10提升12.1%的显著效果-6。
混合架构:融合LLM与多模态知识图谱,在稀疏交互条件下召回率提升约2%~5%-22。
7.2 向量数据库与Embedding
Embedding是将文本(选科政策、专业描述)转换为数值向量的技术,是RAG检索环节的基础。sBERT等模型因其能在本地运行、无API成本的特点,在教育推荐场景中得到广泛应用-5。
7.3 图神经网络与知识推理
图卷积网络(GCN)等技术被用于聚合多模态特征和高阶交互关系,实现课程之间、学生之间的结构化推理-22。这类技术让选科AI助手不仅能“找到相关专业”,还能“解释为什么推荐这个专业”。
八、高频面试题与参考答案
面试题1:请解释RAG的工作原理及其在选科推荐中的应用
参考答案要点:
RAG = Retrieval(检索)+ Augmented(增强)+ Generation(生成)
工作流程:用户提问 → 向量检索(从知识库查找相关文档) → 上下文拼接 → LLM生成回答
选科场景优势:确保回答基于最新政策(而非LLM训练数据的过时信息),避免幻觉,支持限定知识访问
踩分点:讲清三个阶段、说明与纯LLM的区别、给出具体场景示例
面试题2:大模型推荐和传统协同过滤推荐的核心区别是什么?
参考答案要点:
数据依赖:传统方法依赖密集的用户-物品交互矩阵;LLM方法可在冷启动下仅凭内容理解做推荐
语义理解:传统方法无法理解“我喜欢学物理但讨厌数学”这种复合语义;LLM可以进行深层意图解析
效果对比:实验表明,LLM推荐在CTR任务上AUC提升可达5%,在序列推荐任务上NDCG@10提升可达170%-42
代价:LLM推理效率显著低于传统方法,不适合毫秒级实时推荐
踩分点:既要说出优势,也要指出局限,体现辩证思考
面试题3:如何解决选科推荐中的冷启动问题?
参考答案要点:
内容理解兜底:利用LLM分析学生输入的文本描述(兴趣、优势、职业倾向)作为初始推荐依据
知识图谱推理:基于课程/专业的结构化关系进行推理,不依赖历史交互
多模态融合:结合心理测评、学科能力测试等多维度数据-47
迁移学习:利用大规模预训练模型的知识迁移能力
踩分点:突出“无历史数据也能推荐”的核心思路,分点作答
面试题4:Graph RAG与普通RAG的区别是什么?
参考答案要点:
普通RAG检索基于向量相似度(语义相似),无法理解实体间的逻辑关系
Graph RAG引入知识图谱,检索时既考虑语义相似,也沿着图谱路径进行多跳推理
选科场景优势:能理解“计算机专业→需要物理基础→物理成绩不好需慎重”这类链式推理
踩分点:抓住“普通RAG找相似,Graph RAG做推理”的核心差异
面试题5:请简述选科AI助手的整体架构
参考答案要点:
用户交互层:自然语言问答接口,支持对话式交互
意图理解层:LLM解析用户需求,提取关键信息(学科优势、目标专业、地区政策)
检索推理层:RAG检索政策文档 + 知识图谱关系推理,双路并行
推荐生成层:LLM融合多路信息,生成结构化推荐报告
踩分点:画出架构思维导图,说清每一层职责和数据流向
九、结尾总结
本文系统梳理了选科AI助手的技术体系,核心知识点回顾:
| 知识点 | 核心要点 |
|---|---|
| 传统推荐痛点 | 语义理解薄弱、冷启动失效、数据稀疏、排序逻辑缺失 |
| RAG(核心概念) | 检索增强生成 = 检索外部知识 + 增强LLM输入 + 生成准确回答 |
| 知识图谱(关联概念) | 结构化关系表示,与RAG形成“检索+推理”双轮驱动 |
| 关系总结 | RAG处理非结构化文本,KG处理结构化关系,LLM做融合决策 |
| 底层技术 | LLM + 向量Embedding + 图神经网络 + 知识推理 |
| 面试重点 | RAG原理、传统vs LLM推荐、冷启动解法、Graph RAG区别、系统架构 |
易错点提示:
❌ 误以为RAG和KG是替代关系 → ✅ 两者是互补协作关系
❌ 忽略LLM推荐的低效率问题 → ✅ 实际部署需考虑推理延迟
❌ 面试只背概念不讲场景 → ✅ 每个技术点都要结合选科场景说明
选科AI助手的技术仍在快速演进——从“单一LLM”到“RAG+KG混合架构”,从“通用大模型”到“垂直领域决策模型”,值得持续关注-14。下一篇我们将深入探讨Graph RAG在图数据库中的具体实现与性能优化,欢迎持续关注。