上海羊羽卓进出口贸易有限公司
上海羊羽卓进出口贸易有限公司一、AI热点小助手:为何成为2026年信息洪流中的“必备神器”
随着各大社交平台每日产生海量信息,传统人工筛选热点不仅耗时费力,更容易遗漏真正高价值的情报。这正是AI热点小助手应运而生的核心驱动力。它集大语言模型(Large Language Model,LLM)、RAG检索增强生成(Retrieval-Augmented Generation)与Agent智能体等前沿技术于一身,能够自动抓取多平台数据,通过AI智能过滤低价值内容、去重、分类与提炼,最终输出最具决策价值的热点信息-1。
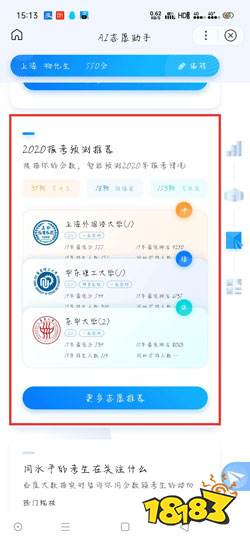
对于在校学生、技术入门者、面试备考者和开发者而言,理解AI热点小助手背后的技术逻辑,不仅有助于构建完整的知识体系,更能让你真正“知其然,更知其所以然”。本文将从痛点切入,由浅入深地拆解核心概念,辅以代码示例和面试考点,帮助读者建立完整的技术认知链路。
二、痛点切入:传统热点采集方式为什么不行了?

在AI热点小助手出现之前,热点信息采集主要依赖以下几种方式:
传统实现方式代码示例:
传统方式:手动筛选 + 简单爬虫 import requests from bs4 import BeautifulSoup 痛点1:需要为每个平台单独写爬虫逻辑 def fetch_weibo_hot(): 微博热榜爬虫代码(约50行) pass def fetch_zhihu_hot(): 知乎热榜爬虫代码(约50行) pass 痛点2:数据格式不统一,需要大量清洗 def clean_data(raw_data): 手动处理各平台异构数据 pass 痛点3:人工筛选低价值内容 manual_filtered = [] 靠人眼看,效率极低
传统方式的三大痛点:
多平台异构:不同平台的API接口、数据格式、访问限制各不相同,采集难度大-49;
实时性差:传统爬虫方案受限于请求频率,难以实现毫秒级热点更新-49;
内容质量参差:娱乐八卦、广告营销、重复内容大量涌现,核心情报被淹没-1。
这些问题催生了AI热点小助手的技术创新——通过MCP标准化协议和LLM智能过滤,彻底解决传统方案的痛点-49。
三、核心概念:大语言模型(LLM)——AI热点小助手的“大脑”
标准定义: 大语言模型(Large Language Model,LLM)是基于Transformer架构,通过海量文本数据进行预训练,拥有数十亿乃至万亿参数的人工智能模型-。
生活化类比: 如果把AI热点小助手比作一个团队,LLM就是这个团队的“大脑”——一个学富五车的学霸,能读懂你的意图,进行逻辑推理,甚至读懂潜台词-3。
作用与价值: 在AI热点小助手中,LLM负责理解用户查询意图、从抓取的热点数据中提取关键信息、进行语义理解与总结提炼,是整套系统的核心驱动引擎。
最新行业动态(2026年4月):
DeepSeek V4即将发布:据DeepSeek创始人梁文锋透露,新一代旗舰大模型DeepSeek V4将于4月下旬正式发布,速度提升35倍、能耗降低40%-23-。4月8日,DeepSeek已在网页端率先上线“快速模式”与“专家模式”,首次引入模式分层设计-20。
GPT-5已正式上线:2026年4月9日,GPT-5正式发布,支持400k上下文,相比GPT-4的128K提升了300%,能够一次性分析完整的技术文档或处理大规模代码库-。
阿里千问Qwen3.6-Plus:4月2日发布的新模型全面提升了编程Coding和Agent能力,发布仅1天即登顶OpenRouter日榜榜首,日调用量突破1.4万亿Token--68。
四、关联概念:RAG(检索增强生成)——AI热点小助手的“实时资料库”
标准定义: RAG(Retrieval-Augmented Generation,检索增强生成)是一种将外部知识检索与生成式AI相结合的技术架构,通过从向量数据库中检索相关文档片段,为大模型生成答案提供可靠的上下文依据。
RAG与LLM的关系: LLM是“基础大脑”,而RAG是给这个大脑配备的“实时查资料小助手”-3。LLM的知识截止于训练数据,而RAG让AI能够实时获取最新信息,有效解决模型“知识过时”和“幻觉”问题-41。
为什么AI热点小助手离不开RAG? 热点资讯具有极强的时效性——今天的头条新闻昨天还不存在。仅靠LLM训练数据中的知识,无法回答“今天有什么最新热点”。RAG通过实时检索最新数据,让AI助手摆脱“过时记忆”,始终保持信息新鲜度-3。
RAG运行机制示例:
用户提问:"今天AI领域有什么大新闻?" ↓ RAG检索模块:实时抓取并检索最新AI资讯数据库 ↓ 检索到相关片段:DeepSeek上线专家模式、GPT-5发布、Qwen3.6-Plus发布 ↓ LLM生成模块:基于检索内容,组织生成结构化回答 ↓ 最终输出:今日三大AI热点,附详细信息与来源
五、概念关系总结
| 概念 | 角色定位 | 核心职责 | 典型应用 |
|---|---|---|---|
| LLM(大语言模型) | 大脑 | 语义理解、逻辑推理、文本生成 | 理解用户意图、总结热点 |
| RAG(检索增强生成) | 实时知识库 | 外挂检索、知识补全 | 获取最新热点资讯 |
| Agent(智能体) | 手脚 | 任务拆解、工具调用、自主执行 | 自动抓取多平台数据、定时推送 |
| MCP(模型计算协议) | 通信协议 | 标准化服务接入 | 一键接入9大中文热榜 |
一句话记住: LLM是大脑,RAG是实时知识库,Agent是手脚,三者协同构成完整的AI热点小助手技术栈-3。
六、代码实战:搭建一个简易AI热点助手
以下是一个基于Python的极简版AI热点助手核心逻辑,突出LLM调用 + RAG检索的完整流程:
简易AI热点助手核心实现 import requests import json class SimpleAIHotspotAssistant: def __init__(self, api_key): self.api_key = api_key self.llm_endpoint = "https://api.openai.com/v1/chat/completions" 步骤1:多平台热点抓取(模拟RAG检索) def fetch_hotspots(self, platforms=["weibo", "zhihu", "36kr"]): """抓取多平台热点数据""" 实际实现中:调用各平台API或MCP服务 hotspots = { "weibo": ["DeepSeek上线专家模式", "GPT-5正式发布"], "zhihu": ["如何看待DeepSeek V4即将发布?"], "36kr": ["阿里Qwen3.6-Plus日调用量破1.4万亿"] } return hotspots 步骤2:RAG检索增强(去重、过滤、排序) def rag_retrieve(self, raw_data): """RAG检索:去重 + 智能过滤""" all_news = [] for platform, news_list in raw_data.items(): for news in news_list: all_news.append({"title": news, "source": platform}) AI智能去重(基于语义相似度) unique_news = self.deduplicate_by_semantic(all_news) return unique_news def deduplicate_by_semantic(self, news_list): """基于语义的去重逻辑(简化版)""" 生产环境使用Embedding模型计算相似度 seen_titles = set() unique = [] for item in news_list: if item["title"] not in seen_titles: seen_titles.add(item["title"]) unique.append(item) return unique 步骤3:LLM生成热点总结 def generate_summary(self, hotspots): """调用LLM生成结构化热点报告""" prompt = f""" 请根据以下热点资讯,生成一份简洁的热点总结报告: {json.dumps(hotspots, ensure_ascii=False)} 输出格式要求: 1. 按重要性排序 2. 每条热点包含:标题、核心事件、影响分析 """ response = requests.post( self.llm_endpoint, headers={"Authorization": f"Bearer {self.api_key}"}, json={ "model": "gpt-4", "messages": [{"role": "user", "content": prompt}], "temperature": 0.3 降低随机性,确保输出稳定 } ) return response.json()["choices"][0]["message"]["content"] 完整流程:抓取 → 检索 → 生成 def run(self): print("🤖 AI热点助手启动中...") print("📡 步骤1:多平台热点抓取") raw_data = self.fetch_hotspots() print("🔍 步骤2:RAG检索去重与过滤") filtered = self.rag_retrieve(raw_data) print("✨ 步骤3:LLM智能生成热点总结") summary = self.generate_summary(filtered) print("\n📊 === 今日AI热点总结 ===\n") print(summary) return summary 使用示例 if __name__ == "__main__": assistant = SimpleAIHotspotAssistant(api_key="your_api_key") assistant.run()
代码关键点说明:
RAG检索层:
fetch_hotspots+rag_retrieve模拟了从多平台获取数据并进行智能过滤的过程;LLM生成层:
generate_summary调用大模型对检索结果进行结构化总结;温度参数:设置
temperature=0.3确保热点总结的稳定性和准确性,避免“放飞自我”。
对比改进效果:
| 维度 | 传统方式 | AI热点小助手 |
|---|---|---|
| 平台覆盖 | 单平台/需手写爬虫 | 多平台一键接入 |
| 去重能力 | 人工判断 | 语义级自动去重 |
| 生成效率 | 人工整理数小时 | 秒级生成 |
| 质量一致性 | 依赖个人水平 | 结构化输出,稳定可靠 |
七、底层原理支撑
AI热点小助手背后的核心技术依赖以下底层基础:
Transformer与自注意力机制:自2017年Transformer架构诞生以来,自注意力机制赋予模型捕获全局关联的能力-。这是LLM能够理解长文本语义的核心。2026年3月,Kimi团队提出的Attention Residuals论文进一步揭示了深度注意力机制的优化方向-30。
向量化与Embedding:RAG检索的关键在于将文本转化为向量嵌入,在向量数据库中进行相似度检索-41。截至2026年,已有IDC数据预测,超过60%的企业级AI应用将采用RAG架构-41。
Function Calling(工具调用) :Agent智能体能够主动调用外部工具完成具体任务,依赖于LLM API的Function Calling能力-40。这使AI从“聊天工具”进化为能“动手办事”的实用帮手-3。
MCP协议标准化:MCP(ModelScope Compute Protocol)协议实现了热点服务的标准化接入,一键覆盖9大中文平台热榜-49。2026年,OpenClaw等开源项目进一步推动了AI热点助手的本地部署能力-1。
混合专家模型(MoE) :通过MoE架构在保持高性能的同时实现效率最大化,DeepSeek V4速度提升35倍、能耗降低40%-。
八、高频面试题与参考答案
Q1:请简述LLM和RAG的核心区别及适用场景。
参考答案:
LLM(大语言模型) :是经过海量数据预训练的基础模型,核心能力是语义理解与文本生成,但知识截止于训练数据。适用于通用对话、文本创作、代码生成等场景。
RAG(检索增强生成) :是一种技术架构,通过外挂知识库检索来增强LLM的回答能力。适用于需要实时信息、企业私有知识问答、避免幻觉等场景。
一句话总结:LLM是“大脑”,RAG是“外挂知识库”——LLM决定“怎么说”,RAG决定“说什么”。
回答要点:面试官期待听到“外挂知识库”“幻觉缓解”“实时信息”这三个关键词--。
Q2:如何解决大模型的“幻觉”问题?
参考答案:
结构化约束:强制模型输出JSON格式,并在System Prompt中定义严格的Schema-58;
RAG知识库拒答机制:注入“不知为不知”指令,让模型在找不到答案时直接回复“不知道”而非编造-58;
思维链引导(CoT) :要求模型先输出思考过程和参考资料片段,再给出最终答案-58;
Few-Shot示例:提供3-5个标准问答对,让模型模仿严谨风格-58。
Q3:请解释Transformer中的自注意力机制及其作用。
参考答案:
自注意力机制(Self-Attention)允许模型在处理一个单词时,同时关注句子中的所有单词,并计算每个单词对当前单词的“重要性权重”。
核心公式:
Attention(Q,K,V) = softmax(QK^T/√d_k) · V,其中缩放因子1/√d_k用于防止点积值过大导致梯度消失-65。作用:捕获全局依赖关系,让模型理解上下文语义。
Q4:微调(Fine-tuning)和RAG该如何选择?
参考答案:
RAG解决“信息缺失” :当任务需要实时信息、最新知识或企业内部文档时,优先选择RAG,无需重新训练模型-;
微调重塑“表达偏好” :当任务重风格、重一致性(如品牌话术、特定口吻),且知识相对静态时,微调更可控-;
工程建议:80%的长尾需求通过RAG解决,20%的核心场景再考虑微调-40。
Q5:Agent智能体是如何实现“自主执行”的?
参考答案:
Agent的核心是LLM的Function Calling能力——LLM能够理解API定义并生成正确的调用参数-40;
工作流程:用户指令 → LLM理解意图并拆解任务 → 决定调用哪些工具(API) → 执行并返回结果 → 整合输出-41;
示例:让AI“帮我分析今日热点并生成报告”,Agent会自主调用热点抓取API、RAG检索、LLM生成,最终输出结构化报告。
九、总结与展望
本文核心知识回顾:
| 知识点 | 核心内容 | 一句话总结 |
|---|---|---|
| LLM | 基于Transformer的大语言模型 | AI的“大脑”,负责理解和生成 |
| RAG | 检索增强生成技术 | 给大脑配一个实时资料库 |
| Agent | 智能体,具备任务拆解与工具调用能力 | 让AI能“动手办事” |
| MCP协议 | 标准化服务接入 | 一键接入9大热榜 |
重点强调: AI热点小助手的本质是 LLM(大脑)+ RAG(知识库)+ Agent(手脚) 三大核心技术的协同应用。理解三者的分工与协作,是掌握当前AI应用开发的基石。
下一站预告: 下一篇将深入剖析Agent智能体的工具调用机制,并带你动手实现一个完整的“AI新闻助手”项目,涵盖多Agent协作、任务编排与生产级部署方案。